
In previous articles, I discussed two of the four major trends driving a new look at document capture solutions, now often referred to as Intelligent Document Processing (IDP). The first two articles covered aspects associated with the ability to work on documents previously untouchable by capture solutions and new applications of machine learning enabling IDP to be more accessible.
This article covers a third major trend that extends concepts of document automation to cover unstructured documents such as insurance policies and contracts. The data within unstructured documents are commonly needed in the full claims submission-to-payment reconciliation process.
This key factor deals with the evolution (or in some respects, a revolution) in how IDP software can enrich document-based information in order to improve overall results. The most common term used is “context.” It is probably a good thing to explain what that is, giving the term “context” some context!
Defining Context
The Oxford English dictionary defines context as “the situation in which something happens and that helps you to understand it.” Another definition is more specific, “the words that come just before and after a word, phrase or statement, and help you to understand its meaning.
With any type of software where the primary task is to make meaning out of unstructured information, context is king. Even for “easy” structured forms, context is required in the form of user-supplied locations and expected data types of form fields. For semi-structured documents, such as an Explanation Of Benefits (EOB), context often comes in the form of keywords or labels for data along with correlations with other data on a document.
Examining Types of Context
When it comes to more complex data such as unstructured insurance policies, property deeds or other document-based data that does not lend itself to coordinates or labels, we have to consider another type of context: grammatical. Often referred to as part of Natural Language Processing (NLP), grammatical context takes the words and sentences on a page and supplements them with data about what types of words they are such as nouns, pronouns, subjects, etc. This process isn’t magic; it’s much like the process of structuring sentences that many of us learned how to do in school.
Using common rules and constructs of a particular language, a tool will parse the text and “enrich’ the base data. From there, the outcomes along with this labeled data are processed by various machine learning algorithms to arrive at reliable ways to automate locating hard-to-find data.
Insurance Policy – An Example
Here’s an example of a homeowners insurance policy where the task is to verify certain coverage. We start with the targeted text:
For each individual covered under one or more policies up to a total of $500,000 for basic hospital, medical-surgical and major medical insurance, $300,000 for disability or long term care insurance, and $200,000 for other types of health insurance.
Next, we parse it through what is called a parts-of-speech-tagger that yields the following:

We then tag the data that we want:

And then, we import this example (plus many hundreds or thousands more) into machine learning algorithms that discover the best ways to reliably locate and output what we really want:
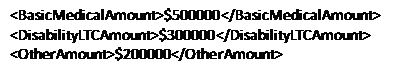
The Last Mile: Context and Machine Learning
This new context is the essential ingredient to expand the range of use cases of IDP software into realms of problems which previously only humans have been able to solve.
If you have the need to find important information in unstructured documents such as life insurance policies, medical records, property deeds, health provider contracts, self-insured commercial policies or any other multi-page unstructured data, grammatical context coupled with machine learning is the key.
These are the problems that Parascript is truly excited about solving, and we’re investing a lot of our efforts to address this “last mile” of the most expensive and most complex automation problem.


