

Part 7 in our series focuses on the reliability of OCR tools. The fact is that most Intelligent Capture software is complex. The result is that few organizations really plan to achieve straight through processing (STP) through the use of field-level confidence score thresholds. What happens if an organization invests the necessary time and resources to achieve STP? Will it be successful? The answer is, more often than not, “no.”
In Part 6, I ended with an ominous warning (“the ugly truth”) regarding use of confidence scores and potential lack of reliability. The effect is that organizations often review 100% of their data and in most implementations, this unfortunate fact is the only way to assure high quality data.
One of the most common inquiries that we receive is the ability to improve a process, which already uses “OCR.” (Note: I place OCR in quotes because there is a lot more that goes into Intelligent Capture than use of OCR.) The main problem typically revolves around the desire to capture more data than the current system. A typical objective associated with this desire is to also reduce the amount of manual data entry.
Often, this then leads to how much data they must currently review and correct. The answer is almost always 100%. That is, 100% of data is reviewed by staff who then make a determination of whether particular data fields need to be corrected. After examining the situation, we typically find that the output along with associated confidence scores are not up to the task of achieving reliable automated verification. Why is this?
Over Reliance on OCR Tools
There is a good reason most people closely associate Intelligent Capture solutions with OCR: most of these solutions use OCR and probably grew out of solutions offering more simple capabilities such as document imaging. Many times organizations create their own solutions using OCR toolkits. For simple needs, creating a custom solution using off-the-shelf OCR is completely reasonable. For instance, using OCR to convert images into searchable text is a perfect task for most OCR toolkits.
However, when it comes to using OCR for turning document-based information into highly-reliable structured data, the requirements quickly outstrip the capabilities of OCR toolkits and the developers using them. This is because OCR was primarily created to solve a single task: transcribe text on a scanned document into machine-readable text. In this regard, little to no attention is paid to the accuracy of specific data fields. Accuracy is measured at the character and/or word level for all the data on the page.
Character-Level and Word-Level Accuracy Limitations
This focus on character-level and word-level accuracy generally results in good accuracy for converting images into searchable text. However, it provides very limited capability to output reliable confidence scores at a data field level versus at a character or word level. In other words, use of off-the-shelf OCR tools may get you accurate page-level data. And yet, without significant modification of the OCR tools themselves and additional development on top of the OCR results, a project (that requires knowing when data is accurate or not) cannot attain straight through processing.
Another problem is that many solutions implement a lot of rules that focus on validation of data, but these rules are run only after receiving output from OCR. So solutions might check output against a dictionary or other list of expected values, or process the output using pattern recognition to detect if the output is accurate. These efforts don’t do anything for the confidence score itself; scores from OCR are not changed and therefore, they cannot be used to establish a reliable threshold. The only way to potentially improve reliability of confidence scores is to use this type of validation during the process of recognition, which can help the OCR engine make a better selection of presenting the correct answer.
STP Requires Reliable Confidence Scores
In Part 6, we covered how confidence scores can be used to identify a threshold that establishes—at a statistical level—good data from bad. After analysis of a sizable amount of data, we can set thresholds that represent specific accuracy levels. For instance, with invoice data extraction, we can set a threshold of 70 for “Total Amount” that means 88% of all Total Amounts are extracted with 98% accuracy. That is a fairly precise statement. And precision requires reliability. What happens when OCR cannot output reliable field-level confidence scores? Instead of getting a range of data and scores that allow sorting to identify a threshold, such as what is seen in figure 1, you end up getting a range that offers no ability to identify a threshold at all as can be seen in figure 2.
Figure 1. Range of Data & Reliable Scores with Threshold

Figure 2. Range of Data & Unreliable Scores where no Threshold can be Established
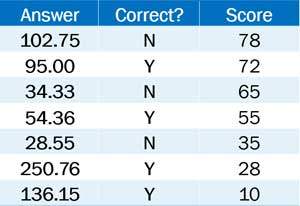
Note that in both cases, the accuracy level of output is the same: four of seven fields are correct. But the output in figure 2 is not reliable when confidence scores are examined. Plenty of inaccurate data have relatively high scores and vice versa. The example of amounts is probably an easier task but the more complex the data, the more difficult it is for general OCR tools to output reliable field-level confidence scores. Without reliability, organizations are stuck reviewing 100% of their data.
OCR Designed for Intelligent Capture
The example provided above isn’t just representative of custom projects that use off-the-shelf OCR tools. Intelligent Capture solutions can have the same problems and for the same reasons. While these solutions offer a bevy of functions designed to improve accuracy and validate the data, the same unreliability problems of confidence scores remain. That is where a special breed of OCR can help.
Designed for data fields and not for page-level results, special-purpose OCR is built to work with specific data on a page, each with a particular data type, and each with its own range of potential values and business requirements. All this additional information is used during the data field recognition process, not after.
Ensure that only suspect data is reviewed, leaving the bulk of accurate data to pass straight into business workflows and applications.
This type of specialized OCR is trained on specific data types to not only provide high levels of accuracy, but to also output confidence scores that are reliable at a data field level. This means that with enough analysis, very stringent thresholds can be identified and used to control output. This ensures that only suspect data is reviewed, leaving the bulk of accurate data to pass straight into business workflows and applications. Banks all over the world use Parascript software because of both its accuracy and reliability. This results in over 90% cost reductions.
Can organizations enjoy automation with off-the-shelf OCR? Sure. But if the ultimate goal is to achieve high levels of automation without the need for manual intervention, OCR tools fall well short.
In Part 8, we’re going to dig into what we find when engaging with clients and the underlying reasons that most of today’s Intelligent Capture software cannot really deliver on the promise of STP.
###
If you found this article interesting, you may find this executive briefing on What Is Accuracy? useful.



